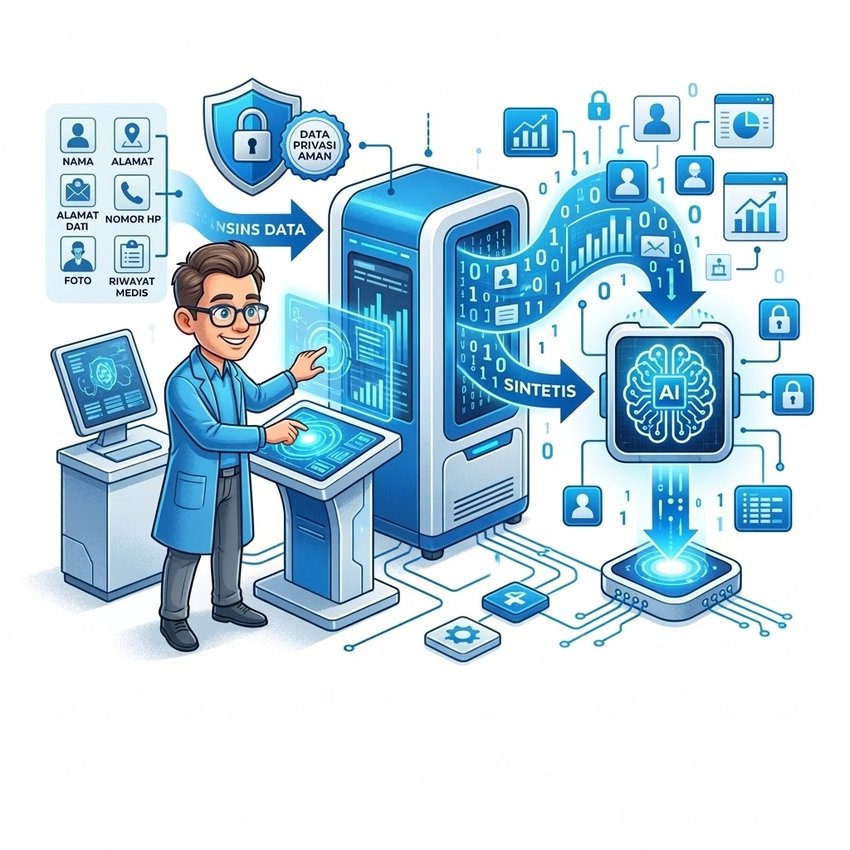
Pernahkah Anda membayangkan melatih sistem kecerdasan buatan dengan data yang sebenarnya tidak pernah ada? Kedengarannya seperti fiksi ilmiah, namun inilah yang sedang terjadi di dunia teknologi saat ini. Synthetic data atau data sintetis muncul sebagai solusi cerdas untuk salah satu dilema terbesar dalam pengembangan AI: bagaimana melatih model yang akurat tanpa mengorbankan privasi pengguna.
Apa Itu Synthetic Data dan Bagaimana Cara Kerjanya?
Synthetic data adalah data buatan yang dihasilkan secara algoritmis untuk meniru karakteristik statistik data asli tanpa mengandung informasi personal yang sebenarnya. Bayangkan seperti membuat foto wajah seseorang yang tidak pernah eksis, wajah tersebut terlihat nyata, memiliki semua fitur manusia normal, tetapi tidak merepresentasikan individu yang sebenarnya.
Proses pembuatan synthetic data umumnya melibatkan beberapa teknik utama:
- Generative Adversarial Networks (GANs): Dua jaringan neural yang saling berkompetisi untuk menghasilkan data yang semakin realistis
- Variational Autoencoders (VAEs): Model yang mempelajari distribusi data asli dan menghasilkan sampel baru dari distribusi tersebut
- Agent-based modeling: Simulasi perilaku agen-agen virtual yang menghasilkan data interaksi
- Rule-based synthesis: Pembuatan data berdasarkan aturan dan batasan yang telah ditentukan
Mengapa Synthetic Data Menjadi Sangat Penting?
Ketika seseorang bersentuhan dengan konsep synthetic data seperti mengerjakan proyek machine learning untuk sebuah startup kesehatan. Pasti membutuhkan ribuan rekam medis untuk melatih model diagnosis, tetapi regulasi HIPAA membuat akses ke data pasien nyata hampir mustahil. Di sinilah synthetic data menjadi penyelamat.
Beberapa alasan utama mengapa teknologi ini semakin vital:
- Regulasi privasi yang semakin ketat: GDPR di Eropa, CCPA di California, dan UU PDP di Indonesia membatasi penggunaan data personal
- Kelangkaan data berkualitas: Beberapa skenario seperti kasus fraud atau kecelakaan langka tidak memiliki cukup data historis
- Biaya akuisisi data tinggi: Mengumpulkan dan melabeli data asli membutuhkan waktu dan sumber daya signifikan
- Bias dalam data asli: Data sintetis dapat dibuat lebih seimbang dan representatif
Aplikasi Nyata Synthetic Data di Berbagai Industri
Penerapan synthetic data telah merambah berbagai sektor industri dengan hasil yang mengejutkan:
Industri Otomotif dan Kendaraan Otonom
Waymo dan Tesla menggunakan jutaan mil data simulasi untuk melatih sistem self-driving mereka. Menciptakan skenario berbahaya seperti pejalan kaki yang tiba-tiba menyeberang atau kondisi cuaca ekstrem jauh lebih aman dan praktis dalam lingkungan virtual dibanding pengujian nyata.
Sektor Keuangan dan Perbankan
Lembaga keuangan saat ini sudah memanfaatkan synthetic data untuk melatih model deteksi fraud. Data transaksi sintetis memungkinkan mereka mengekspos model ke berbagai pola penipuan tanpa risiko kebocoran data nasabah.
Tantangan dan Keterbatasan yang Perlu Diwaspadai
Meskipun menjanjikan, synthetic data bukanlah solusi sempurna. Berdasarkan pengalaman saya dan diskusi dengan praktisi di lapangan, beberapa tantangan signifikan masih ada:
Fidelity gap menjadi masalah utama, synthetic data mungkin tidak sepenuhnya menangkap nuansa dan edge cases dari data asli. Dalam proyek saya sebelumnya, model yang dilatih dengan data sintetis menunjukkan akurasi 94% pada data sintetis tetapi turun menjadi 87% ketika diuji dengan data nyata.
Risiko lain termasuk:
- Membership inference attacks: Penyerang potensial mungkin dapat menyimpulkan apakah data tertentu digunakan dalam pelatihan generator
- Mode collapse: Generator mungkin hanya mempelajari subset terbatas dari distribusi data asli
- Validasi yang sulit: Bagaimana membuktikan bahwa synthetic data cukup representatif tanpa membandingkannya dengan data asli yang seharusnya dilindungi?
Perkembangan Terkini dan Tren Masa Depan
Tahun 2024-2025 menyaksikan kemajuan signifikan dalam domain ini. Gartner memprediksi bahwa pada 2030, synthetic data akan melampaui data asli dalam pelatihan AI. Beberapa tren yang patut diperhatikan:
Diffusion models seperti yang mendasari Stable Diffusion dan DALL-E kini diadaptasi untuk menghasilkan tabular data dan time series dengan kualitas lebih tinggi. Startup seperti Mostly AI, Gretel, dan Tonic.ai telah mengumpulkan ratusan juta dolar investasi.
Kolaborasi antara regulator dan industri juga meningkat. UK Financial Conduct Authority dan Bank of England telah mengeluarkan panduan penggunaan synthetic data, memberikan legitimasi pada pendekatan ini.
Langkah Praktis untuk Memulai dengan Synthetic Data
Bagi Anda yang tertarik mengeksplorasi teknologi ini, berikut panduan memulai:
- Identifikasi use case: Mulai dengan proyek di mana privasi menjadi blocker utama
- Pilih tools yang tepat: SDV (Synthetic Data Vault) untuk Python adalah titik awal yang baik dan open-source
- Validasi secara menyeluruh: Gunakan metrik statistik seperti KL divergence dan utilitas downstream
- Iterasi dan perbaiki: Synthetic data generation adalah proses iteratif, bukan one-time task
Refleksi: Masa Depan Data yang Tidak Pernah Ada
Synthetic data menandai pergeseran paradigma dalam cara kita memikirkan data dan privasi. Ini bukan tentang menggantikan data asli sepenuhnya, melainkan menciptakan ekosistem di mana inovasi AI dapat berkembang tanpa mengorbankan hak privasi individu.
"Data terbaik untuk melatih AI masa depan mungkin adalah data yang tidak pernah berasal dari siapapun." Pernyataan ini awalnya terdengar paradoks, tetapi semakin masuk akal seiring perkembangan teknologi synthetic data.
Bagi para profesional TI dan data scientist, memahami dan menguasai teknologi ini bukan lagi pilihan, ini adalah keharusan untuk tetap relevan di era di mana privasi dan kemampuan AI harus berjalan beriringan.